

Antes de desenhar uma solução de monitoramento de condição, é necessário definir uma ferramenta ou conjunto de ferramentas capazes de possibilitar a convergência IT-OT, através dos 5 pontos listados a seguir.
1) Gerir eficientemente dados em tempo real, oriundos de uma grande variedade de fontes operacionais;
2) Capturar e armazenar dados de fluxo contínuo, de forma fidedigna;
3) Fornecer um diretório de dados, capaz de organizar fluxos de dados e informações de processo. É recomendável que essa estrutura esteja organizada conforme a árvore de ativos e a topologia da planta;
4) Ser capaz de análises avançadas, capaz de converter fluxos de dados brutos em eventos e informações significativas;
5) Possibilitar a visualização dos dados de forma clara e multiplataforma, a fim de possibilitar a demoractiação dos dados.
C – Passos para Data Science e projetos de CBM O advento da Indústria 4.0 traz entre seus pilares, a internet das coisas, o big data, o processamento em nuvem e a inteligência artificial. A coleta de dados aliada ao aumento da capacidade de armazenamento e processamento, permite que modelos e algoritmos de aprendizado de máquina se tornem cada vez mais populares em um contexto industrial.
O Cross Industry Standard Process for Data Mining, CRISP-DM, representado na Figura 5, pode ser definido como uma metodologia recorrente entre cientistas de dados para análise de dados. A implementação de uma solução CBM deve ser encarada como um processo de melhoria contínua e não um projeto de curto prazo. É possível estabelecer um paralelo ao ciclo PDCA e à metodologia CRISP-DM, sendo as etapas de Entendimento do Negócio, Compreensão dos Dados e Preparação dos Dados relacionadas à fase de Planejar; Modelagem relacionada à Fazer; Avaliação relacionada à Verificar e Implementação relacionada a ajustar. Deste modo, mesmo que exista um volume limitado de informações referentes ao ativo, é possível iniciar um projeto de CBM, pois este será refinado e o modelo será retreinado.

II – IMPLEMENTANDO O CBM
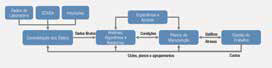
O processo de CBM inicia-se com o monitoramento de parâmetros específicos de ativos; considerando a avaliação desses parâmetros em relação a seus limites e tendências. A conclusão deste processo está na
integração da solução a uma ferramenta de gerenciamento de manutenção, como um CMMS, Computerized Maintenance Management System.
A Figura 6 ilustra o fluxo de dados em tempo real, oriundos tanto dos sensores em campo, armazenados em um historiador, quanto das atividades de manutenção executadas, planos de manutenção vigentes e do FMEA, Failure Modes and Effect Analysis. O processo de monitoramento do ativo evolui à medida que novos dados são coletados e percepções de especialistas são aplicadas ao modelo. Para a implementação de um monitoramento baseado em condição, é necessária a aplicação dos passos descritos a seguir.
A – Defina um piloto
Os critérios de escolha de um piloto convergem para uma análisede custo/benefício, levando em consideração a representatividade do ativo nos custos totais de manutenção, os custos adicionais do
Caio Huais é engenheiro industrial, especialista em Engenharia Elétrica e Automação com MBA em engenharia de manutenção e gestão de negócios. Atualmente, ocupa posição de gerente corporativo de manutenção no Grupo Equatorial, respondendo pelo desempenho da Alta Tensão de 7 concessionárias do Brasil. Evolução da gestão de ativos: Implementação de condição em tempo real através de
dados históricos online Parte 2/2 Por Fernanda Alves de Souza* e Caio Huais 69 *Fernanda Alves de Souza é Consultora em Confiabilidade e Smart Operations – Alvarez & Marsal. Msc. Engenharia Elétrica -UFMG
impacto no negócio e outros impactos (tais como ambientais, saúde e segurança) para uma avaliação completa do retorno financeiro. Neste processo de escolha, os seguintes aspectos devem ser abordados:
1) A disponibilidade de sensores para monitoramento da condição de ativos e seus modos de falha. Os seus principais modos de falha são monitoráveis? Quais variáveis podem ser medidas para possibilitar a
detecção destes modos de falha? Essas variáveis já são monitoradas ou necessitam a aquisição de novos sensores?
2) Qual o nível de conhecimento existente? A companhia já desenvolveu um monitoramento semelhante em outro ativo? Há informação disponível na literatura técnica sobre o monitoramento dos modos de falha detectáveisou será necessário uma pesquisa e desenvolvimento de novas soluções?
3) Qual a complexidade do processo? Processos com alta variabilidade e diferentes regimes e regiões de operação podem adicionar uma complexidade extra à etapa de tratamento dos dados.
A resposta a estes questionamentos permitirá a equipe avaliar em uma matriz de impacto e esforço, qual equipamento candidato apresenta maior viabilidade e deverá ser o escolhido.
É importante salientar a necessidade de equilibrar o retorno sobre o investimento, a complexidade do projeto e o impacto nos indicadores de produtividade e disponibilidade da companhia.
B – Organize as informações disponíveis
Após a definição do piloto, o processo de preparação e coleta das informações do ativo é iniciado. Alguns dados que tornarão o processo mais rápido e assertivo são listados a seguir.
1) FMEA. O FMEA servirá de guia para identificar quais os modos de falha possíveis e quais destes são detectáveis. Determinando os modos de falha detectáveis será possível definir variáveis que necessitam ser monitoradas, caso este monitoramento não exista atualmente.
2) Lista de TAGs no Historiador. Quais são os itens e variáveis já monitorados do ativo? Há itens ainda não monitorados que permitem a detecção de modos de falha, conforme descrito no FMEA? Mesmo sem a cobertura completa de todos os modos de falha detectáveis através de instrumentação e monitoramento, o processo pode ser inicializado considerando os modos já cobertos. Paralelamente, iniciativas para instalação de dispositivos IoT poderá ser executada, refinando mais ainda o modelo após a aquisição destes dados.
3) Ocorrências de Falhas e Ordens de Manutenção. Quais os modos de falha mais recorrentes? Com as informações disponíveis atualmente é possível implementar um CBM capaz de detectar, mesmo que parcialmente, as falhas mais recorrentes?
4) Parâmetros de Processo e Limites operacionais do Ativo. Quais os parâmetros operacionais do processo e os limites do equipamento? O ativo está operando além de sua capacidade nominal e, portanto, em região de deterioração forçada?
C – Análise Exploratória dos Dados
Após a coleta, limpeza e organização dos dados, é necessário permitir que os dados falem por si. Estatísticas descritivas, correlações entre as variáveis e eventos conhecidos podem servir de um ponto de partida para compreender o comportamento do ativo.
D – Defina a técnica
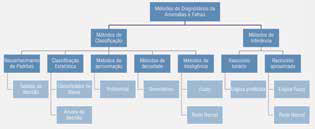
Nesta etapa, é interessante avaliar se o funcionamento do equipamento pode ser descrito através de modelos baseados em formulação física, ou uma abordagem através algoritmos de reconhecimento de padrões é mais recomendada. Uma combinação de técnicas também poderá ser utilizada, a escolha será influenciada pelas percepções observadas na etapa de análise e exploração dos dados.
A Figura 7 representa um esquemático de diferentes técnicas e abordagens para a construção de um modelo para diagnóstico e detecção de anomalias.
E – Avalie o desempenho
Reserve um percentual dos dados para treinamento e a segunda parte para validação dos dados. Compare os resultados previstos aos eventos observados e estabeleça um nível de acurácia. Também é necessário observar se os cenários de underfitting ou um overfitting, conforme Figura 8, estão acontecendo no modelo. O desempenho não será satisfatório em nenhum destes cenários.

F – Refina o modelo
À medida que novos dados são gerados, somada à deterioração natural de todo ativo, o modelo necessitará de ajustes de modo a garantir a acurácia desejada.
G – Integre ao CMMS
Os planos de manutenção baseados no calendário poderão ser substituídos por planos a evento, cuja regra estará relacionada ao resultado dos algoritmos para detecção de anomalias, gerando automaticamente a ordem de serviço. Neste contexto, o sistema funcionará de modo prescritivo: detectando a falha e, em sequência, a ação corretiva a ser executada.

Por Fernanda Alves de Souza* e Caio Huais